퇴직 예정인 선임 엔지니어의 책상 서랍에는 수십 년치 메모가 있다. 장비가 이상하게 울릴 때 어떤 파라미터를 먼저 보는지, 특정 로트에서 반복되는 현상을 어떻게 판단하는지 — 그 판단 기준은 매뉴얼 어디에도 없다. 그리고 그 엔지니어가 퇴직하는 날, 그 지식은 함께 사라진다.
지식 아카이브는 이 문제를 해결하기 위한 구조다. 흩어져 있던 노하우를 체계적으로 수집하고, 누구든 검색해서 꺼내 쓸 수 있는 형태로 보존하는 것 — 이 글에서는 지식 아카이브의 개념부터, RAG 기술을 활용해 챗봇으로 연결하는 전체 구조까지 한 번에 정리한다.
지식 아카이브란 무엇인가
지식 아카이브(Knowledge Archive)는 조직 안에 흩어진 노하우와 경험 지식을 장기 보존 가능한 형태로 정리해 쌓아둔 저장소다.
여기서 핵심은 “장기 보존”과 “꺼내 쓸 수 있는 형태” 두 가지다. 단순히 파일을 쌓아두는 것은 아카이브가 아니다. 나중에 검색하고 활용할 수 있도록 구조화된 상태여야 한다.
지식에는 두 종류가 있다.
| 구분 | 정의 | 예시 |
|---|---|---|
| 형식지 (Explicit Knowledge) | 문서화된 지식. 누구나 읽을 수 있는 형태 | 매뉴얼, 작업 표준서, 보고서 |
| 암묵지 (Tacit Knowledge) | 경험에서 축적된 지식. 말로 설명하기 어려운 형태 | 베테랑의 판단 기준, 현장 감각, 구두 전달 노하우 |
지식 아카이브의 진짜 목표는 암묵지를 형식지로 전환해 저장하는 것이다. 퇴직, 이동, 조직 개편 — 어떤 상황이 오더라도 지식이 사라지지 않도록 만드는 구조다.
지식이 사라지는 3가지 순간
지식 아카이브가 왜 필요한지 이해하려면, 먼저 지식이 어디서 증발하는지를 알아야 한다.
첫째, 사람이 떠날 때다. 퇴직, 팀 이동, 이직 — 경험 많은 엔지니어가 자리를 비울 때 가장 많은 노하우가 함께 빠져나간다. 인수인계서에는 절차만 있고 판단 기준은 없다.
둘째, 구두 전달은 기록이 안 된다. 현장에서 “이럴 때는 이렇게 해”라는 말은 수도 없이 오간다. 하지만 그 순간을 지나치면 흔적이 없다. 누군가의 머릿속에만 남아있는 지식은 언제든 사라질 수 있다.
셋째, 문서가 있어도 못 찾는다. 작성된 보고서, 트러블슈팅 이력, 회의록 — 어딘가에 분명히 있는데 찾을 수가 없다. 검색이 안 되는 문서는 없는 것과 같다. 지식 아카이브는 이 세 가지 문제를 동시에 해결하는 구조다.
지식 아카이브가 작동하는 구조 — 수집에서 검색까지
지식 아카이브는 크게 3단계로 작동한다.
1단계: 수집 (Collect)
노하우의 원천은 다양하다. 기존 문서, 회의록, 트러블슈팅 이력, 작업 메모, 그리고 베테랑 엔지니어의 인터뷰까지. 이 원천 데이터를 한 곳으로 끌어모으는 것이 첫 번째다. 형태는 텍스트, PDF, 음성 전사 파일 등 다양하게 허용된다.
2단계: 정제 및 DB화 (Structure & Store)
수집된 데이터를 그냥 쌓아두면 검색이 불가능하다. 여기서 구조화 작업이 들어간다. 핵심 개념을 추출하고, 태그를 붙이고, 검색 가능한 형태로 변환한다. RAG 구조에서는 이 단계에서 텍스트를 벡터(Vector) 형태로 변환해 벡터 DB에 저장한다. 벡터는 텍스트의 의미를 숫자 배열로 표현한 것으로, 비슷한 의미를 가진 내용끼리 가깝게 배치되는 특성이 있다.
3단계: 검색 및 도출 (Retrieve & Generate)
이제 질문을 던질 수 있다. “장비 A에서 진동이 발생할 때 어떤 파라미터를 먼저 확인해야 하나?” — 이 질문이 들어오면 시스템은 벡터 DB에서 가장 관련성 높은 노하우를 꺼내오고, AI가 이를 바탕으로 답변을 생성한다.
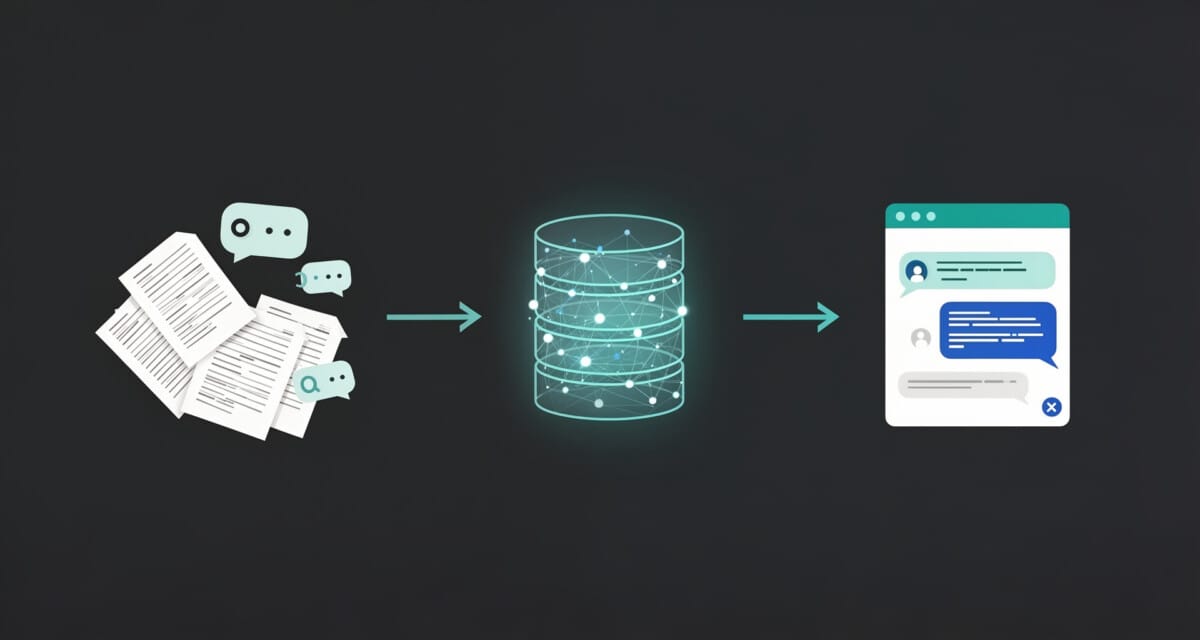
[원천 데이터] [아카이브] [활용]
문서, 회의록, 메모 → 벡터 DB 저장 (구조화) → RAG 챗봇 검색·답변
구두 전달 전사본 (지식 아카이브) 질문 → 관련 노하우 추출
RAG 챗봇은 아카이브를 어떻게 꺼내 쓰는가
RAG(Retrieval-Augmented Generation)는 “검색 강화 생성”이라는 뜻이다. 일반적인 AI 챗봇이 학습 데이터만으로 답변을 만드는 것과 달리, RAG는 외부 DB에서 관련 정보를 먼저 검색한 뒤 그것을 근거로 답변을 생성한다.
지식 아카이브에 RAG를 연결하면 이런 흐름이 만들어진다.
- 사용자가 챗봇에 질문을 입력한다
- 챗봇이 질문을 벡터로 변환해 아카이브 DB에서 유사한 내용을 검색한다
- 검색된 노하우 조각들을 AI에게 컨텍스트로 넘긴다
- AI가 그 노하우를 바탕으로 자연어 답변을 생성한다
핵심은 AI가 없는 답을 만들어내지 않는다는 점이다. 아카이브에 저장된 내용 안에서만 답을 찾는다. 이것이 일반 챗봇과 지식 아카이브 기반 RAG 챗봇의 가장 큰 차이다.
| 구분 | 일반 AI 챗봇 | RAG 기반 챗봇 |
|---|---|---|
| 답변 근거 | AI 학습 데이터 | 조직 내부 아카이브 |
| 신뢰성 | 일반 지식 수준 | 조직 맥락에 맞는 노하우 |
| 할루시네이션 위험 | 높음 | 낮음 (검색 기반) |
| 업데이트 방식 | 재학습 필요 | DB 추가만으로 가능 |
베테랑 엔지니어의 판단 기준이 아카이브에 쌓여 있다면, 신입 엔지니어도 챗봇을 통해 그 노하우에 접근할 수 있다. 지식 아카이브는 경험의 민주화다.
지식 아카이브 구축 전 반드시 알아야 할 3가지
개념을 이해했다고 해서 바로 구축이 되는 건 아니다. 현장에서 실제로 만들어보면 이 3가지에서 막힌다.
첫째, 쓰레기가 들어가면 쓰레기가 나온다. 아카이브의 품질은 투입되는 원천 데이터의 품질에 달려있다. 모호한 문장, 맥락 없는 메모, 잘못된 이력 — 이런 데이터를 넣으면 챗봇의 답변도 그 수준에 머문다. 수집 단계에서 정제 기준을 명확히 세우는 것이 첫 번째 과제다.
둘째, 노하우를 텍스트로 만드는 것 자체가 작업이다. 베테랑의 판단 기준은 말로 표현되지 않는 경우가 많다. “그냥 느낌으로 안다”는 말을 텍스트로 변환하는 인터뷰, 관찰, 전사 작업이 필요하다. 이 단계를 건너뛰면 아카이브는 이미 문서화된 지식만 담게 된다.
셋째, 아카이브는 살아있어야 한다. 한 번 구축하고 끝이 아니다. 새로운 트러블슈팅 이력이 생기면 추가하고, 오래된 정보는 업데이트해야 한다. 유지 관리 주체와 프로세스가 없으면 아카이브는 빠르게 낡는다.
핵심 요약
지식 아카이브는 사라질 수 있는 조직의 노하우를 수집·구조화해 검색 가능한 형태로 보존하는 저장소다. RAG 챗봇을 연결하면 그 아카이브가 살아있는 검색 시스템이 된다. 구축의 핵심은 기술보다 “어떤 지식을 어떻게 텍스트로 만들 것인가”라는 설계 질문에 있다.
지식 아카이브의 핵심 엔진인 RAG가 내부적으로 어떻게 작동하는지 구조부터 잡고 싶다면 아래 글이 이어진다.
지식 아카이브를 조직 전체에 도입하는 흐름은 AX(AI Transformation)와 맞닿아 있다. 개념이 낯설다면 이 글을 먼저 읽어보자.
AX 뜻 완전 정복 — DX 다음에 온 AI 전환이 현장을 바꾸는 3가지 방식
암묵지·형식지 개념 참고 — IBM Think – IBM Think — Knowledge Management: 암묵지와 형식지의 차이
RAG 기술 구조 참고 — LangChain 공식 문서 – LangChain 공식 문서 — RAG 개념과 Q&A 구조