F1 레이스에서 이런 상황을 상상해보자. 새 시즌을 앞두고 팀이 외부에서 최고로 평가받는 엔지니어를 영입한다. 이론은 완벽하고 데이터 분석 실력도 탁월하다. 그런데 그는 우리 머신의 콕핏에 한 번도 앉아본 적이 없고, 이 차가 어느 코너에서 어떻게 미끄러지는지 손끝으로 느껴본 적이 없다. 셋업 시트는 교과서대로 나오는데, 정작 차가 어디서 무너지는지를 모른다.
AX 실패의 본질이 정확히 이 장면이다. 기술이 부족해서 생기는 게 아니라 “누가 하느냐”를 틀려서 무너진다. AI를 잘 아는 외부 전문가에게 전부 맡기는 순간, 실패는 이미 예약된다. 이 글에서는 AX가 왜 자꾸 같은 자리에서 무너지는지, AX 실패를 만드는 세 가지 구조적 원인과, 현장 엔지니어가 직접 나서야 하는 이유를 정리한다.
AX란 무엇이고 왜 자꾸 실패하는가
AX(AI Transformation)는 AI를 업무 프로세스 안에 내재화해서 일하는 방식 자체를 다시 설계하는 것이다. 도구 몇 개를 도입하는 수준이 아니라, 업무가 돌아가는 골격을 AI 기준으로 바꾸는 작업이다.
문제는 현장에서 이게 거의 매번 같은 방식으로 무너진다는 데 있다. 수십억을 들여 사내 AI 시스템을 구축해도 직원들은 그 시스템을 거의 열지 않는다. 정작 손에 든 스마트폰의 범용 챗봇은 하루에도 몇 번씩 쓴다. 회사가 만든 시스템에는 볼 게 없고, 범용 챗봇은 물어보면 바로 답이 나오기 때문이다. 이 간극이 AX 실패의 첫 신호다.
AX 실패의 원인 3가지
원인을 뜯어보면 결국 사람과 조직의 문제로 모인다. 기술 스택이 아니라 일을 누구에게 맡겼는지가 결과를 가른다.
1. 아무도 쓰지 않는 시스템 — 남이 만들면 안 쓴다
사람은 자기가 직접 만든 도구는 쓴다. 반대로 누군가 “이거 쓰세요” 하고 완성해서 던져준 시스템은 잘 안 쓴다. 만들어진 시점에는 최선이었어도 1년만 지나면 모델도 데이터도 구형이 되고, 범용 챗봇과 비교하면 콘텐츠 품질 차이가 크게 벌어진다. 결국 비싼 시스템은 방치되고 사용 로그만 비어간다. AX 실패의 가장 흔한 형태가 바로 이 “안 쓰는 시스템”이다.
2. 도메인을 모르는 전문가 — 문제 정의를 못 한다
AI가 끝내 못 하는 단 하나가 문제 정의다. AI가 잘하는 건 이미 정의된 문제를 푸는 일이고, 무엇을 풀어야 하는지는 업무를 아는 사람만 정할 수 있다. “불량을 줄여달라”고만 던지면 AI는 “어떤 공정의, 어떤 불량을 말하느냐”고 되묻는다.
장치산업의 자동화 라인 하나만 해도 원자재 투입부터 완제품 출하까지 수많은 단계를 거치고, 어디서 문제가 시작됐는지는 그 라인을 매일 보는 사람만 짚어낼 수 있다. 테마를 정하고, 필요한 데이터셋을 고르고, 전처리 기준을 잡는 앞단은 전부 현업의 몫이다. 앞단을 현업이 채우지 못하면 뒷단의 AI 전문가는 손댈 거리가 없다. 이 앞뒤가 끊기는 지점이 두 번째 AX 실패 원인이다.
3. 오너십의 공백 — 책임질 사람이 없다
프로젝트의 주인이 누구냐는 질문에 많은 회사가 “AI 팀”이라고 답한다. 이게 결정적인 착오다. AI를 직접 쓸 현업 팀이 오너십을 쥐지 않으면, AI 조직은 회의에서 점점 밀려나고 조용히 고립된다. 보여주기용 결과물만 쌓이다 끝난다.
책임 문제도 같은 뿌리에서 나온다. AI에 할루시네이션이 있다는 건 모두 안다. 병원은 의사가, 법률은 변호사가 최종 책임을 지듯 기업의 결정도 결국 사람이 책임져야 한다. 그런데 “네가 담당자니 책임져라”라고 하면 현업은 차라리 옛날 방식으로 돌아가겠다고 한다. 만든 사람도, AI도, 보고받은 사람도 아무도 책임지지 않는 공백 — 이것이 세 번째 AX 실패 원인이다.
그래서 현업이 직접 바이브 코딩을 해야 한다
세 가지 원인의 답은 하나로 모인다. 쓸 사람이 직접 만들고, 문제를 아는 사람이 정의하고, 결정의 주인이 책임진다. 그 실행 도구가 바이브 코딩이다. 자연어로 흥얼거리듯 요구사항을 쓰면 코드가 나오는 방식이라, AI 전문가가 아니라 현장 엔지니어가 직접 자기 업무 도구를 만들 수 있다.
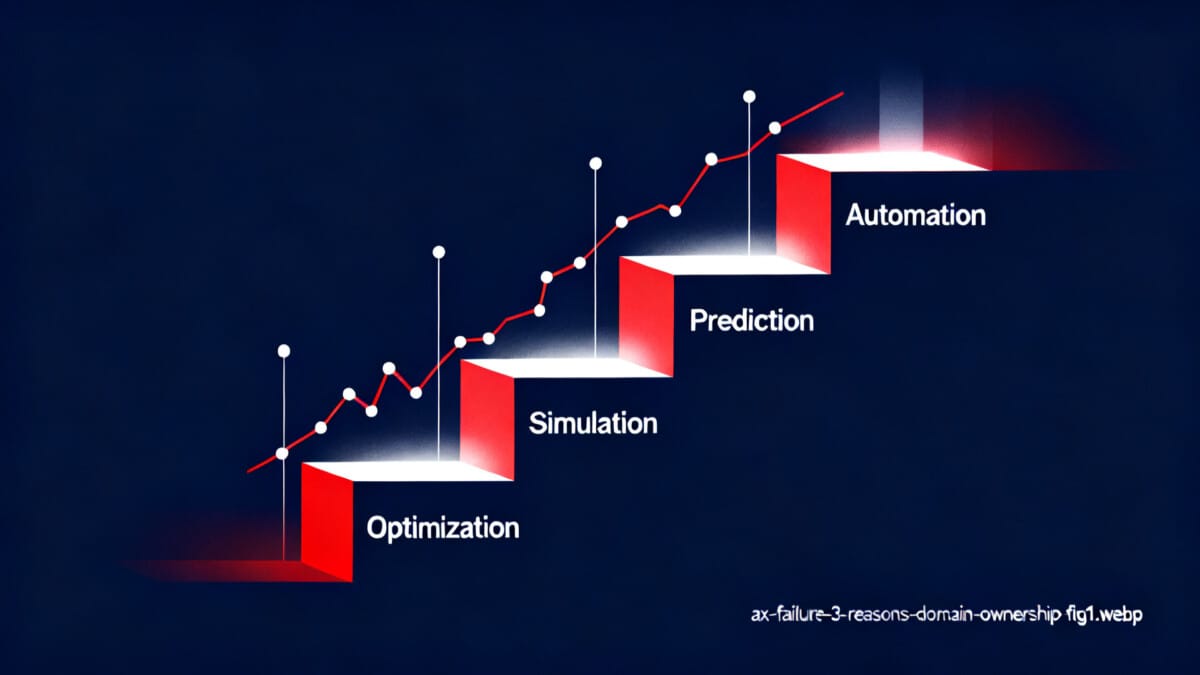
다만 자동화에서 멈추면 절반만 한 것이다. 8시간 걸리던 일을 1시간에 끝내고 남은 7시간을 흘려보내면 또 다른 실패의 얼굴이 된다. 자동화 다음에는 네 단계를 차례로 밟아야 한다.
F1 레이스에서 이런 상황을 다시 상상해보자. 한 시즌 동안 모든 랩의 텔레메트리를 쌓는다고 하자. 데이터를 자동으로 모으는 것이 1단계, 쌓인 기록에서 다음 랩타임을 내다보는 것이 2단계, 타이어 마모와 피트 타이밍을 바꿔가며 결과를 돌려보는 것이 3단계, 가장 적은 비용으로 가장 빠른 랩을 만드는 조합을 찾는 것이 4단계다.
이 시나리오는 개념 설명을 위한 가상의 상황입니다. 실제 F1 팀의 전략과 다를 수 있습니다.
| 단계 | 하는 일 | 필요한 것 | 결과 |
|---|---|---|---|
| 1. 자동화 | 데이터 수집·반복 업무 처리 | 업무 정의 | 시간 확보 |
| 2. 예측 | 쌓인 데이터의 패턴 관찰 | 누적 기록 | 미래 추정 |
| 3. 시뮬레이션 | 요인을 바꿔 결과 비교 | 예측 모델 | 시나리오 비교 |
| 4. 최적화 | 최소 비용·최대 성과 조합 탐색 | 시뮬레이션 | 의사결정 근거 |
확보한 7시간을 이 사다리를 오르는 데 쓰면, 자동화는 단순한 비용 절감에서 경쟁력으로 바뀐다.
전사로 퍼질 때 반드시 생기는 문제 — 섀도우 IT
전 직원이 하루 한 개씩 앱을 만들면 금세 수천 개가 쌓인다. 여기서 통제 없이 두면 새로운 혼란이 생긴다. 같은 매출을 두고 A가 만든 보고서와 B가 만든 보고서 숫자가 다르고, 표준이 없으니 저마다 자기 방식대로 만들며, 내부 데이터가 외부로 새는 길이 늘어난다.
| 문제 | 원인 | 영향 |
|---|---|---|
| 데이터 불일치 | 데이터 출처·기준이 제각각 | 보고서 숫자 충돌 |
| 가이드라인 부재 | 표준·규칙 없음 | 품질 편차 |
| 보안 노출 | 데이터 흐름 통제 불가 | 유출 위험 |
그래서 IT 부서의 역할이 바뀐다. 개별 도구를 막는 게 아니라, 전사가 안전하게 바이브 코딩을 할 수 있는 플랫폼을 깔고 그 아래 벡터 DB·그래프 DB 같은 데이터 자산 계층을 다시 만드는 일이다. 사람이 읽는 보고서 형식과 AI가 다루기 좋은 데이터 형식은 다르다. AI가 쓰기 좋은 형태로 사내 자산을 가공하는 인터페이스 계층 — 여기가 앞으로 큰 가치가 생기는 자리다.
핵심 요약
AX 실패는 기술 문제가 아니라 사람과 조직의 문제다. 정리하면 이렇다.
- 남이 만든 시스템은 안 쓴다 → 쓸 사람이 직접 만든다
- 도메인 없는 전문가는 문제 정의를 못 한다 → 앞단(정의·데이터)은 현업이 맡는다
- 오너십이 AI 팀에 가면 고립된다 → 현업 팀이 주인이 되고 책임도 진다
- 자동화에서 멈추지 말고 예측·시뮬레이션·최적화까지 올라간다
- 전사 확산 시 IT는 통제가 아니라 안전한 플랫폼과 데이터 계층을 제공한다
AX 실패를 피하려면 결국 현업이 직접 도구를 만들어야 한다. 그 첫 설계 원칙부터 잡고 싶다면 이어서 읽어보자.
AI가 코드와 분석을 대신해도 인간의 역할이 사라지지 않는 이유가 궁금하다면 이 글이 답이 된다.
바이브 코딩이라는 개념의 출발점은 Google Cloud의 vibe coding 설명에서 더 알아볼 수 있다.