F1 레이스에서 이런 상황을 상상해보자.
피트 월에 앉아 있는 전략 엔지니어는 수백 개의 센서 수치를 보며 한 가지 질문을 반복한다. “지금 이 수치가 정상 범위에서 나온 것인가, 아니면 뭔가 달라진 세계에서 나온 것인가.” 그 판단 하나가 레이스 전체를 바꾼다.
통계적 가설검정이 하는 일이 정확히 이것이다. 여기까지 시리즈를 따라온 독자라면, 이미 그 판단 구조의 핵심을 손에 쥐고 있다. 이 글에서는 지금까지 쌓은 내용이 어떤 큰 틀을 이루는지 조감하고, 통계 검정 종류가 어떤 방향으로 뻗어 나가는지 정리한다.
가설검정은 계산이 아니라 의사결정 구조다
많은 엔지니어가 통계를 처음 접할 때 이렇게 생각한다. “공식을 외우고 숫자를 대입하면 되는 것 아닌가.”
그렇지 않다. 통계 검정 종류가 수십 가지여도, 본질은 하나다 — 확률을 근거로 한 의사결정이다.
H₀는 현재의 통념이다. “공정은 정상이다”, “타이어는 아직 버틴다”, “평균은 바뀌지 않았다.” 누군가 뒤집을 이유를 제시하기 전까지 기본값으로 유지되는 입장이다. H₁은 엔지니어가 세운 새로운 견해다. “뭔가 달라진 것 같다”, “평균이 변했다”, “이 수치는 예전과 다르다.” 현장 경험에서 나온 직관이 수식이 되는 순간이다.
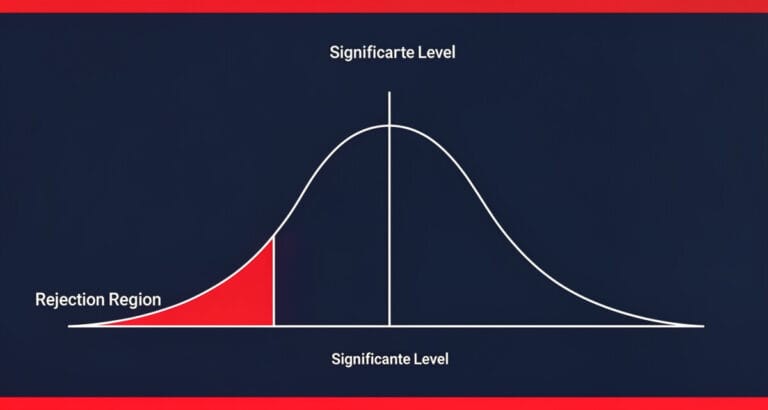
가설검정은 이 둘을 놓고 확률 싸움을 붙인다. “지금 수집한 표본 데이터가 H₀ 세계에서 나올 법한가, 아니면 H₁ 세계에서 나올 법한가.” p-value는 그 확률 싸움의 점수판이다. α는 엔지니어가 미리 정해둔 판정 기준선이다.
이 구조를 이해하면, 통계 검정 종류가 달라져도 흔들리지 않는다. t-검정이든, F-검정이든, 카이제곱 검정이든 — 형태는 달라도 “H₀ vs H₁, 확률로 판정한다”는 뼈대는 동일하다.
지금까지 이해한 것이 통계 검정의 핵심 골격이다
잠깐 지금까지의 내용을 조감해보자.
| 개념 | 의미 | 역할 |
|---|---|---|
| H₀ vs H₁ | 통념 vs 새 견해 | 판단의 대상 설정 |
| 샘플링 분포 | 표본 평균들의 분포 | 확률 싸움의 무대 |
| p-value vs α | 확률 점수 vs 판정 기준 | 의사결정의 기준 |
| 1종 오류(α) | 정상을 이상으로 판단 | 엔지니어가 허용할 오류 설정 |
| 2종 오류(β) | 이상을 정상으로 판단 | 더 치명적인 오류 |
| 표본 크기(n) | 분포의 뾰족함 결정 | 검정력의 핵심 조건 |
이 여섯 가지 개념이 맞물리는 방식을 이해하고 있다면, 통계 검정 종류가 바뀌어도 큰 틀은 이미 갖춘 것이다. 나머지는 이 뼈대에 가지와 살을 붙여가는 과정이다.
아래 수치는 개념 설명을 위한 임의의 수치입니다.
F1 팀이 피트 판정을 내릴 때, 타이어 센서가 2개든 20개든, 마모 측정이든 온도 측정이든 — “지금 이 수치가 정상 세계에서 나온 것인가”라는 질문 구조는 바뀌지 않는다. 통계 검정 종류도 마찬가지다.
통계 검정 종류, 여기서 3가지 가지가 뻗어 나간다
뼈대를 이해했다면, 실무에서 이 구조를 제대로 쓰기 위해 붙여야 할 살이 있다.
가지 1. 통계 검정 종류 선택 — 상황에 맞는 도구 고르기
데이터 형태와 비교 대상에 따라 통계 검정 종류가 달라진다.
| 상황 | 통계 검정 종류 |
|---|---|
| 평균 하나를 기준값과 비교 | 단일 표본 t-검정 |
| 두 집단 평균 비교 | 이표본 t-검정 |
| 세 집단 이상 평균 비교 | 일원 분산분석(ANOVA) |
| 비율 데이터 비교 | 비율 검정 |
| 범주형 데이터 독립성 검정 | 카이제곱 검정 |
형태는 달라도 “H₀ vs H₁ 확률 싸움”이라는 뼈대는 그대로다. 통계 검정 종류를 외우는 것보다, 지금 내 데이터가 어떤 상황인지를 먼저 파악하는 것이 핵심이다.

가지 2. 검정력 설계 — 표본 크기를 미리 계산하기
β를 낮추고 신뢰성 있는 검정을 하려면 표본이 얼마나 필요한지를 사전에 계산할 수 있다. 검정력 분석(Power Analysis)이 이것이다. “내가 감지하고 싶은 차이의 크기”와 “허용할 α, β 수준”을 입력하면 필요한 표본 크기가 나온다.
실험 설계 단계에서 반드시 필요한 도구다. 데이터를 다 모은 뒤에 “표본이 부족했다”는 결론이 나오면 이미 늦다.
가지 3. 결과 해석의 함정 — p-value를 잘못 읽는 3가지 패턴
통계 검정 종류를 알아도 자주 틀리는 지점이 있다.
| 함정 | 잘못된 해석 | 올바른 해석 |
|---|---|---|
| 1 | “p < 0.05면 H₁이 맞다” | H₀를 기각할 근거가 충분하다는 뜻 |
| 2 | “p가 작을수록 효과가 크다” | p값은 효과 크기가 아닌 확률값 |
| 3 | 통계적 유의성 = 실질적 유의성 | 현장에서 의미 있는 차이인지는 별개 판단 |
뼈대를 이해했다면 이 함정들도 피할 수 있다. 숫자보다 구조를 먼저 보는 것 — 그게 엔지니어가 통계를 다루는 방식이어야 한다.
핵심 요약
가설검정은 공식 계산이 아니라, H₀(통념) vs H₁(새 견해)의 확률 기반 의사결정 구조다.
| 구분 | 핵심 |
|---|---|
| 골격 | H₀·H₁, 샘플링 분포, p-value, α·β, 표본 크기 |
| 통계 검정 종류 | 데이터 형태·비교 대상에 따라 도구가 달라질 뿐, 뼈대는 동일 |
| 다음 단계 | 검정 방법 선택, 검정력 설계, p-value 해석 함정 |
현장에서 오래 데이터를 봐왔지만, 이 구조를 언어로 정리한 건 통계를 다시 처음부터 들여다보면서였다. 뼈대가 보이기 시작하면, 흩어져 있던 개념들이 한 줄로 연결된다. 그 감각이 이 시리즈를 통해 전달됐으면 한다.
통계 검정 종류를 고르기 전에, p-value를 정확히 읽는 법부터 짚고 가자.
이 시리즈의 출발점으로 돌아가고 싶다면 귀무가설·대립가설부터 다시 확인하자.
수포자도 따라오는 통계 — 슬기로운 통계생활로 기초를 잡아라