지난 포스팅에서 가설 검정의 출발점을 다뤘다. 이번에는 가설검정 P값의 핵심으로 바로 들어간다.
F1 타이어 마모 예시로 이런 가설을 설정했다.
- H₀: 이번 레이스의 타이어 평균 마모량은 기준치 100이다.
- H₁: 이번 레이스의 타이어 평균 마모량은 기준치보다 작다.
레이스 중 실제로 데이터를 수집했더니 표본평균 x̄ = 97.5가 나왔다. 여기서 질문 하나가 남는다.
97.5는 “충분히 다른” 수치인가, 아니면 오차 범위 안인가?
이 질문에 답하는 도구가 가설검정 P값이다. P값, 유의수준, 기각역 — 가설검정의 판단 3요소를 같은 F1 예시로 이어서 풀어낸다. 개념을 한 번 제대로 잡으면, 수식 없이도 판단이 된다.
가설검정 P값이란 무엇인가 — “귀무가설을 지지하는 확률”
P는 Probability, 즉 확률이다. 그렇다면 무슨 확률인가?
가설검정 P값 = 귀무가설이 참이라는 가정 하에, 실제로 수집한 표본 통계량(또는 그보다 더 극단적인 값)이 나올 확률
직관적으로 풀어보자. 만약 “평균 마모량이 100이다(H₀)”라는 가정이 참이라면, 표본평균 x̄은 100 근처에서 나올 가능성이 높다.
| 표본평균 | 해석 | P값 방향 |
|---|---|---|
| x̄ = 99.5 | 100과 거의 차이 없음 → H₀을 지지하는 확률이 높다 | P값 크다 |
| x̄ = 97.5 | 100과 꽤 차이 남 → H₀과 데이터가 잘 맞지 않는다 | P값 작다 |
아래 수치는 개념 설명을 위한 임의의 수치입니다.
F1 레이스에서 이런 상황을 상상해보자.
레이스 중 타이어 마모 데이터를 수집했더니 x̄ = 97.5가 나왔다. 귀무가설(μ = 100)이 참이라고 가정한 샘플링 분포에서, 97.5 이하가 나올 확률을 계산하니 P = 0.022였다.
가설검정 P값이 0.022라는 것은 무슨 뜻인가?
“만약 타이어 평균 마모량이 정말 100이라면, 오늘처럼 97.5 이하의 데이터가 나올 확률은 고작 2.2%에 불과하다.”
확률이 낮다는 것은, 오늘 측정값이 H₀의 세계에서는 이례적인 사건이라는 의미다. “H₀이 맞다면 이런 데이터는 거의 나오지 않아야 하는데, 실제로 나왔다”는 뜻이다. 이 순간 의심이 생긴다. 혹시 H₀이 틀린 게 아닐까?
유의수준이란 무엇인가 — “어디까지 허용할 것인가”의 기준선
가설검정 P값이 작으면 H₀을 의심하게 된다는 건 이해했다. 그런데 얼마나 작아야 “충분히 작다”고 할 수 있는가?
그 기준선이 바로 유의수준(α, significance level)이다.
유의수준은 분석을 시작하기 전에 미리 정해두는 기준 확률이다. 데이터를 보고 나서 편의에 맞게 정하면 의미가 없다.
| 유의수준 | 사용 상황 |
|---|---|
| α = 0.05 | 일반적인 공학·산업 분야 (가장 흔함) |
| α = 0.01 | 의료·약학 등 오류 비용이 큰 분야 |
| α = 0.10 | 탐색적 분석 (실무에서는 드물게 사용) |
판단 기준은 단순하다.
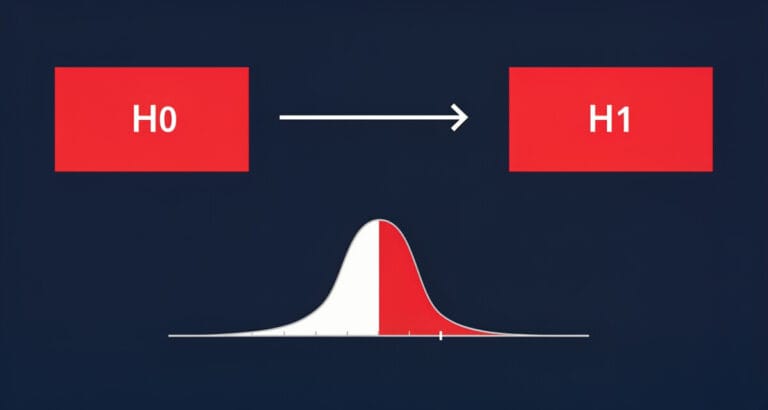
- P값 < α → 귀무가설 기각 → 대립가설 채택 ✅
- P값 ≥ α → 귀무가설을 기각하지 못함 ❌
F1 타이어 예시에 적용하면 이렇다.
F1 레이싱 Engineering 사례는 설명을 위해 구성한 가상의 시나리오다.
실제 특정 팀이나 드라이버의 데이터를 기반으로 한 것이 아님을 밝혀 둔다.
| 항목 | 값 |
|---|---|
| 기준치 (μ) | 100 |
| 측정된 표본평균 (x̄) | 97.5 |
| 유의수준 (α) | 0.05 (사전에 설정) |
| 측정된 P값 | 0.022 |
| 판정 | 0.022 < 0.05 → 귀무가설 기각 → 대립가설 채택 |
결론: “타이어 마모량이 기준치(100)보다 유의미하게 작다. 통계적으로 타이어가 예상보다 잘 버티고 있다.”
이제 피트월의 엔지니어는 자신 있게 드라이버에게 무선으로 전달할 수 있다. “타이어 상태 확인했습니다. 데이터 기준 피트스톱 1회 줄여도 됩니다.” 이것이 가설검정 P값이 현장에서 하는 일이다.

기각역이란 무엇인가 — P값과 같은 말을 다른 방식으로
가설검정 P값으로 판단하는 방식 말고도, 기각역(Rejection Region)과 기각수준(Critical Value)으로 판단하는 방법도 있다.
개념은 동일하다. 단지 확률의 언어를 값의 언어로 바꿨을 뿐이다.
- 기각수준(Critical Value): α = 0.05에 해당하는 x̄의 위치값. “이 값보다 작게 나오면 귀무가설을 기각한다”는 경계선.
- 기각역(Rejection Region): 기각수준을 기준으로, 귀무가설을 기각하는 영역.
| 방식 | 판단 기준 | 결론 |
|---|---|---|
| P값 비교 | P값 0.022 < α 0.05 | 귀무가설 기각 |
| 기각역 비교 | x̄ = 97.5가 기각역 안에 속함 | 귀무가설 기각 |
두 방식은 항상 같은 결론을 낸다. JMP, Python, R 같은 통계 소프트웨어를 쓰면 두 값 모두 자동으로 계산해준다. 실무에서는 가설검정 P값을 기준으로 판단하는 쪽이 더 직관적이고 널리 쓰인다.
핵심 요약
가설검정 P값은 “귀무가설이 참이라고 가정할 때, 지금 이 데이터가 나올 확률”이다. 작을수록 귀무가설과 데이터 사이의 간극이 크다는 뜻이다. 유의수준(α)은 판단의 기준선으로, 분석 전에 미리 정해두며 보통 0.05를 쓴다. P값 < α이면 대립가설을 채택한다.
귀무가설이 기각되지 않을 때 “기각하지 못한다”는 표현을 쓰는 이유도 이제 이해가 될 것이다. 엔지니어는 대립가설이 채택되기를 원하는 경우가 대부분이다. 귀무가설이 채택됐다는 말은, 사실상 “이번엔 아니었습니다”라는 뜻이다.
가설검정 P값을 이해했다면, 다음 질문은 “1종 오류와 2종 오류는 어떻게 제어하는가”다. 검정의 신뢰성을 높이는 원칙이 궁금하다면 이 글을 이어 읽어보자.
P값을 제대로 해석하려면 가설을 올바르게 세우는 법부터 알아야 한다. 처음부터 다시 짚고 싶다면 이 글을 먼저 읽어보자.
영화 F1을 감상하며 Refresh도 하고 Inspiration도 얻어보자