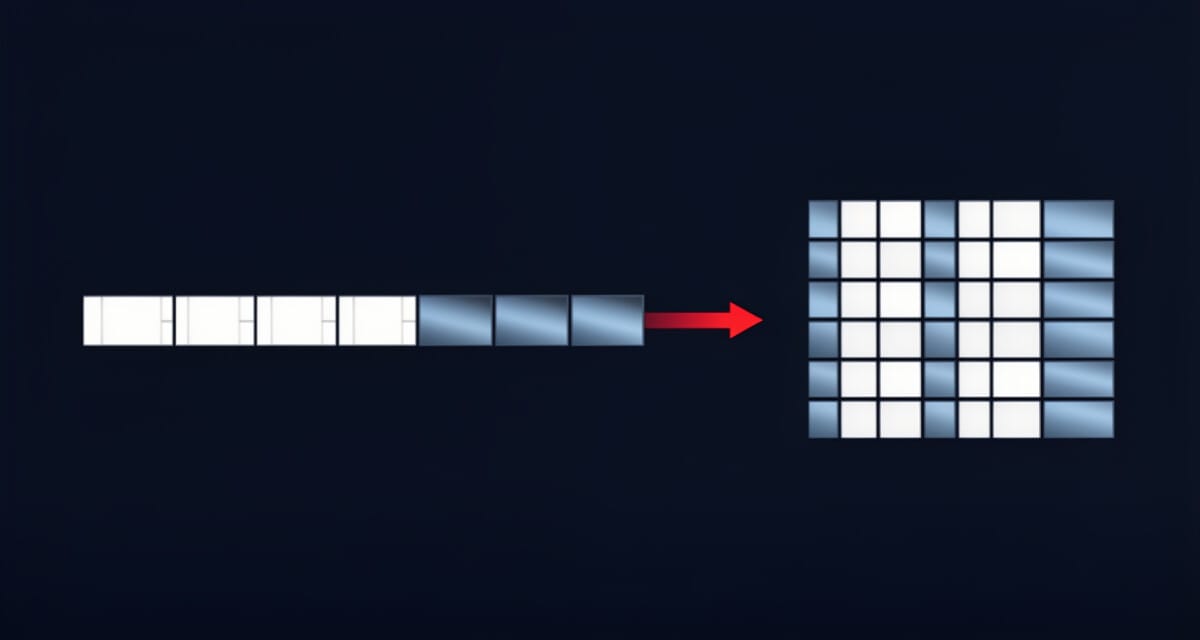
F1 레이스에서 이런 상황을 상상해보자. 피트월의 엔지니어가 랩타임 데이터 1,200개를 손에 쥐고 있다. 이 숫자들을 그냥 줄 세워두면 아무것도 보이지 않는다. 40라운드 × 30랩 구조로 재배치하는 순간, 라운드별 페이스 저하 패턴이 눈에 들어오기 시작한다. NumPy 배열을 다룬다는 건 바로 이 작업이다 — 데이터를 원하는 구조로 빚고, 원하는 위치에서 정확히 꺼내는 것.
요즘은 AI에게 코드를 요청해서 결과를 받는 방식으로 numpy 배열을 다루는 사람이 많다. 그런데 개념을 모르면 AI에게 정확하게 요청할 수가 없다. “배열 만들어줘”와 “결과를 담을 100×3 크기의 0으로 채워진 배열 만들어줘”는 전혀 다른 요청이다. 이 글에서는 numpy 배열을 다루는 5가지 핵심 개념을 판단 기준 중심으로 정리하고, 각 개념을 AI에게 어떻게 요청하면 되는지까지 함께 다룬다.
numpy 배열, 왜 이렇게 많은 생성 함수가 있나
numpy 배열을 처음 배우면 생성 함수가 너무 많아서 당황한다. zeros(), ones(), full(), eye(), empty() — 전부 “배열 만드는 함수”인데 왜 이렇게 많을까. 각각이 쓰이는 상황이 다르기 때문이다. 어떤 상황에 어떤 함수를 골라야 하는지가 핵심이다.
| 함수 | 초기값 | 언제 쓰는가 |
|---|---|---|
zeros() | 0 | 결과를 채워넣을 그릇이 필요할 때 |
ones() | 1 | 곱셈 누산의 초기값, 마스크 기본값 |
full() | 지정값 | 결측값(NaN) 자리나 특정 기본값으로 채울 때 |
eye() | 단위행렬 | 선형대수 연산의 기준값 (PCA, 역행렬 등) |
empty() | 쓰레기값 | 반드시 전부 덮어쓸 것이 확실할 때만 |
empty()는 초기화 시간을 아끼려고 쓰는데, 덮어쓰지 않은 자리에 메모리에 남아있던 값이 그대로 들어온다. 입문 단계에서는 zeros()가 안전하다.
“100개 샘플, 3개 특징값을 담을 numpy 배열을 0으로 초기화해서 만들어줘”
reshape — numpy 배열의 모양을 바꾼다는 게 무슨 뜻인가
reshape는 데이터의 값은 그대로 두고 의미 구조만 재해석하는 작업이다. 메모리를 새로 할당하지 않는다 — 같은 데이터를 다른 렌즈로 보는 것이다.
# 1200개짜리 1D → 40라운드 × 30랩 2D
arr.reshape(40, 30)
숫자 하나 바뀌지 않았는데 의미가 달라진다. 실전에서 reshape가 가장 많이 등장하는 순간은 머신러닝 모델에 데이터를 넣을 때다. 라이브러리마다 요구하는 입력 shape가 다르기 때문에, 같은 데이터를 다른 모양으로 바꿔서 넣어야 하는 상황이 자주 생긴다.
| reshape 전 | reshape 후 | 상황 |
|---|---|---|
(1200,) 1D | (40, 30) 2D | 시계열 데이터 → 라운드별 테이블 |
(784,) 1D | (28, 28) 2D | 픽셀 벡터 → 이미지 복원 |
(100, 24) 2D | (100, 24, 1) 3D | 시계열 → LSTM 입력 포맷 |
조건은 하나 — 전체 원소 수가 같아야 한다. AI에게 요청할 때는 현재 shape과 바꾸고 싶은 shape을 함께 알려주면 정확한 코드가 나온다.
“shape이 (1200,)인 numpy 배열을 (40, 30)으로 reshape하는 코드 짜줘. -1 자동 계산 옵션도 같이 설명해줘”
random — numpy 배열로 난수를 생성하는 3가지 이유
데이터 분석을 하다 보면 데이터가 없는 상황이 생각보다 자주 온다. 실제 데이터가 아직 없거나, 테스트용 가상 데이터가 필요할 때 numpy 배열의 random 함수가 등장한다.
쓰임새는 세 가지로 나뉜다. 첫 번째는 파이프라인 검증이다. 센서 데이터가 없는 상태에서 분석 코드를 미리 짜야 할 때, 실제와 유사한 분포의 가상 데이터를 만들어 전체 흐름을 테스트한다. 두 번째는 머신러닝 가중치 초기화다. 신경망 가중치를 전부 0으로 시작하면 학습이 안 된다. 랜덤값으로 시작해야 뉴런들이 서로 다른 방향으로 학습한다. 세 번째는 실험 재현이다. seed 값을 고정하면 “랜덤이지만 항상 같은 결과”가 나온다. 협업이나 실험 보고에서 필수다.
AI에게 요청할 때는 분포 종류(정규분포·균등분포 등), 평균·표준편차, 배열 크기, 시드 고정 여부를 함께 알려주면 된다.
“평균 100, 표준편차 5인 정규분포를 따르는 numpy 배열 1000개짜리 만들어줘. 재현 가능하도록 시드 고정도 포함해줘”
index vs slicing — numpy 배열에서 차원이 달라지는 이유
NumPy에서 가장 많이 헷갈리는 부분 중 하나다. 같은 데이터를 꺼내는 것 같은데 결과의 shape이 달라진다.
arr # shape (2, 3)
arr[0] # shape (3,) ← 차원 축소
arr[0:1] # shape (1, 3) ← 차원 유지
인덱싱은 차원을 축소하고, 슬라이싱은 차원을 유지한다. 이게 왜 중요한가? sklearn, TensorFlow 같은 머신러닝 라이브러리는 입력 shape에 민감하다. 단일 샘플을 모델에 넣을 때 shape이 (3,)이면 에러가 나고 (1, 3)을 요구하는 경우가 흔하다. numpy 배열을 다루다 shape이 예상과 다르게 나온다면, 십중팔구 인덱싱과 슬라이싱 혼용 때문이다.
| 방식 | 결과 shape | 차원 |
|---|---|---|
arr[0] | (3,) | 축소 |
arr[0:1] | (1, 3) | 유지 |
AI에게 요청할 때 “차원을 유지한 채로” 또는 “2D를 유지하면서”라는 표현을 명시하면 슬라이싱 방식의 코드가 나온다.
“shape (10, 3) numpy 배열에서 첫 번째 행을 차원을 유지한 채로 꺼내는 코드 짜줘”
고급 인덱싱(Fancy Indexing) — 원하는 위치만 한 번에 뽑는 법
기본 인덱싱이 “하나씩” 꺼내는 방식이라면, 고급 인덱싱은 원하는 위치 목록을 배열로 만들어 한 번에 꺼내는 방식이다. 반복문 없이 띄엄띄엄 있는 값을 한 번에 가져올 수 있다.
arr[[0, 2, 4]] # 0번, 2번, 4번 인덱스를 한 번에
2D 배열에서는 행 인덱스 배열과 열 인덱스 배열을 쌍으로 넘긴다. rows[i]와 cols[i]가 묶여서 하나의 좌표가 된다.
실전에서 자주 쓰이는 패턴은 세 가지다. 첫 번째는 특정 샘플 추출 — 알람이 발생한 시점의 인덱스만 골라서 분석할 때. 두 번째는 데이터 셔플과 샘플링 — 머신러닝 train/test split이 내부적으로 이 방식으로 동작한다. 세 번째는 Boolean 인덱싱 — 조건식 자체가 인덱스가 된다.
temp[temp > 30] # 30 초과인 값만 한 번에
고급 인덱싱과 슬라이싱의 결정적 차이는 결과가 copy냐 view냐다.
| 슬라이싱 | 고급 인덱싱 | |
|---|---|---|
| 결과 | view (원본 공유) | copy (새 배열) |
| 원본 수정 영향 | 영향 받음 | 영향 없음 |
고급 인덱싱 결과를 수정해도 원본이 바뀌지 않는다. AI에게 요청할 때 “특정 인덱스만 골라서”, “조건을 만족하는 행만” 같은 표현을 쓰면 고급 인덱싱 코드가 나온다.
“numpy 배열에서 값이 30 초과인 요소만 골라내는 Boolean 인덱싱 코드 짜줘. 원본 배열은 바뀌지 않아야 해”
핵심 요약
numpy 배열을 다루는 모든 도구는 결국 하나의 질문으로 수렴한다 — “이 데이터를 어떤 모양으로, 어떤 라이브러리에 넣을 것인가.” 모양이 맞아야 계산이 돌아가고, 인덱싱 방식이 맞아야 shape이 깨지지 않는다.
AI에게 numpy 배열 코드를 요청할 때 개념을 알고 있으면 요청의 정밀도가 달라진다. 배열 크기와 초기값, shape 변환 전후, 차원 유지 여부, 조건 기반 추출 여부 — 이 네 가지를 명확히 전달할 수 있으면 원하는 코드가 한 번에 나온다.
numpy 배열 조작 개념이 잡혔다면, 다음은 AI에게 집계·난수·인덱싱 작업을 어떻게 요청할지다.
같은 구조로 pandas 인덱싱까지 이어가고 싶다면 이 글이 바로 다음 단계다.
numpy 배열 생성 함수 전체 목록은 공식 문서에서 확인할 수 있다: NumPy 공식 문서 — Array creation