F1 레이스에서 이런 상황을 상상해보자.
세션마다 쌓인 랩 타임 파일이 3개, 드라이버 정보는 별도 테이블, 팀별 평균 랩타임은 따로 뽑아야 한다. 이걸 순서 없이 한꺼번에 처리하려 하면 막힌다. 하지만 흐름을 알면 다르다. 합치고 → 연결하고 → 정렬하고 → 요약한다. 이 4단계가 판다스 데이터 전처리의 전체 흐름이다.
이 시나리오는 개념 설명을 위한 가상의 상황입니다. 실제 F1 팀의 전략과 다를 수 있습니다.
판다스를 AI와 함께 쓸 때도 마찬가지다. 함수 이름이나 코드 문법을 몰라도 된다. 흐름을 알면 “지금 내가 어느 단계에 있는지”를 AI에게 설명할 수 있고, 그 설명이 정확한 코드로 돌아온다. 이 글에서는 판다스 데이터 전처리를 4단계 흐름으로 정리하고, 각 단계에서 AI 프롬프트를 어떻게 구성하면 되는지를 함께 살펴본다. 판다스 데이터 전처리의 흐름을 한 번 잡아두면, 이후 어떤 데이터 작업을 맞닥뜨려도 어느 단계부터 시작할지 바로 보인다.
전처리 흐름을 먼저 잡는다 — 4단계로 구조화하기
판다스 데이터 전처리는 순서가 있다. 이 순서를 모르면 어떤 함수를 써야 할지 막히고, AI에게 요청할 때도 무엇을 먼저 물어봐야 할지 헷갈린다.
| 단계 | 역할 | 대표 함수 |
|---|---|---|
| 1단계 — 수직 결합 | 같은 구조의 데이터를 위아래로 쌓는다 | concat |
| 2단계 — 수평 결합 | 다른 테이블을 키 기준으로 좌우로 붙인다 | merge |
| 3단계 — 정렬 | 인덱스 또는 값 기준으로 순서를 잡는다 | sort_index / sort_values |
| 4단계 — 요약 | 그룹별로 집계하거나 통계로 요약한다 | pivot_table / groupby / describe() |
실무에서 이 4단계를 항상 전부 거치는 건 아니다. 데이터가 이미 하나의 파일이면 1단계는 생략한다. 별도 테이블 연결이 필요 없으면 2단계도 건너뛴다. 중요한 건 내가 지금 어느 단계에 있는지 아는 것이다. 그걸 알아야 AI에게 정확한 단계의 작업을 요청할 수 있다.
1단계 — concat, 흩어진 데이터를 하나로 쌓는다
언제 필요한가
같은 컬럼 구조를 가진 데이터가 여러 파일로 나뉘어 있을 때다. 날짜별 로그, 장비별 측정값, 세션별 기록. 구조는 같고 내용만 다른 데이터를 하나의 DataFrame으로 합치는 것이 concat의 역할이다.
무엇을 결정해야 하는가
concat을 쓸 때 두 가지를 결정해야 한다.
첫째, 인덱스를 새로 부여할 것인가. 각 파일이 0부터 시작하는 인덱스를 갖고 있으면 합친 후 동일한 번호가 중복된다. 이후 데이터 조회에서 예상치 못한 결과가 나오는 원인이 된다. 합친 후 인덱스를 새로 0부터 연속으로 부여할지 결정해야 한다.
둘째, 출처를 표시할 것인가. 합친 후에도 어느 파일에서 온 데이터인지 구분이 필요하다면, 각 DataFrame에 레이블을 붙여서 출처를 남길 수 있다. 날짜나 장비 번호를 레이블로 쓰면 대용량 데이터에서도 추적이 가능하다.
이 두 가지 판단을 내리고 나면 AI에게 이렇게 요청할 수 있다.
“df1, df2, df3 세 개의 DataFrame을 수직으로 합쳐줘. 합친 후 인덱스는 0부터 새로 부여하고, 각 DataFrame의 출처를 ‘session1’, ‘session2’, ‘session3’으로 표시해줘.”
concat이라는 함수 이름을 몰라도 된다. “수직으로 합쳐줘”, “인덱스 새로 부여”, “출처 표시” — 이 세 가지 개념 표현만으로 AI는 정확한 코드를 만들어낸다.
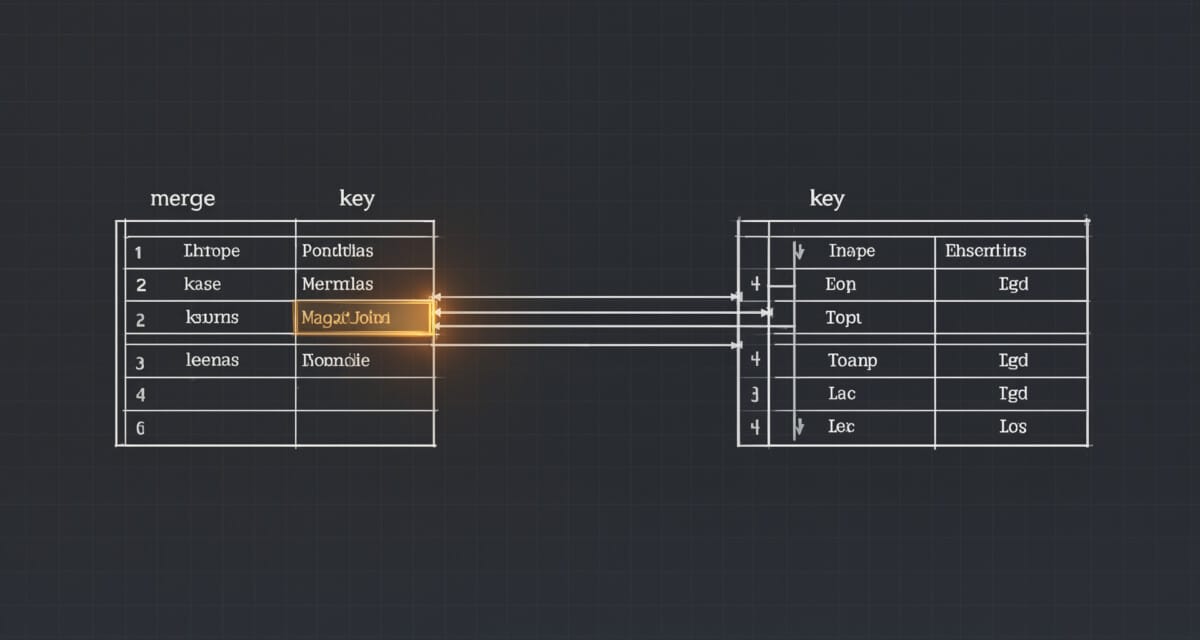
2단계 — merge, 다른 테이블을 키 기준으로 연결한다
언제 필요한가
구조가 다른 두 테이블을 공통 키로 연결해야 할 때다. 랩 타임 데이터에는 드라이버 번호만 있고, 드라이버 이름과 팀 정보는 별도 테이블에 있다. 이 둘을 드라이버 번호를 기준으로 붙이는 것이 merge다. SQL의 JOIN과 동일한 개념이다.
무엇을 결정해야 하는가
merge에서 가장 중요한 결정은 어느 쪽 데이터를 기준으로 합칠 것인가다. 이 결정이 결과의 행 수와 NaN 발생 위치를 결정한다.
| 결정 | 의미 | 언제 쓰는가 |
|---|---|---|
| 공통 key만 남긴다 | 양쪽에 모두 있는 행만 결과에 포함 | 매칭되는 데이터만 분석할 때 |
| 전체를 보존한다 | 없는 값은 NaN으로 채워서 전부 포함 | 데이터 손실 없이 전체를 보고 싶을 때 |
| 왼쪽 기준으로 합친다 | 왼쪽 DataFrame의 모든 행 유지 | 기준 테이블에 정보를 추가할 때 |
| 오른쪽 기준으로 합친다 | 오른쪽 DataFrame의 모든 행 유지 | 참조 테이블 기준으로 볼 때 |
기본값이 “공통 key만 남긴다”는 점이 핵심이다. 명시하지 않으면 한쪽에만 있는 데이터가 결과에서 조용히 사라진다. 분석 전에 어느 쪽 기준으로 합칠지 반드시 결정해야 한다.
이 판단을 내리고 나면 AI에게 이렇게 요청할 수 있다.
“lap_data와 driver_info를 driver_id 컬럼을 기준으로 합쳐줘. lap_data에 있는 모든 행은 유지하고, driver_info에 해당 정보가 없으면 NaN으로 채워줘.”
“왼쪽 기준”, “모든 행 유지”, “없으면 NaN”이라는 표현이 left join을 AI에게 정확하게 전달한다. how=’left’라는 파라미터를 몰라도 개념만 알면 요청이 완성된다.
3단계 — 정렬, 분석 목적에 맞는 순서로 배열한다
언제 필요한가
결합이 끝난 데이터를 원하는 순서로 배열할 때다. 빠른 랩타임 순으로 보고 싶거나, 드라이버 이름 알파벳 순으로 정리하거나, 날짜순으로 재배열해야 할 때 정렬이 필요하다.
무엇을 결정해야 하는가
정렬에서 결정할 것은 두 가지다.
첫째, 무엇을 기준으로 정렬할 것인가. 인덱스나 컬럼명 같은 구조적 기준인가, 아니면 셀 안의 실제 데이터 값인가. 구조를 기준으로 하면 sort_index, 값을 기준으로 하면 sort_values다.
둘째, 오름차순인가 내림차순인가. 작은 값부터 보여줄 것인지, 큰 값부터 보여줄 것인지를 결정한다.
여기에 한 가지가 더 있다. 여러 컬럼을 기준으로 순차 정렬이 필요한 경우다. 드라이버를 1차 기준으로 오름차순 정렬하고, 같은 드라이버 안에서는 랩타임을 2차 기준으로 내림차순 정렬하는 식이다. 이 경우도 개념만 명확하면 요청이 가능하다.
“LapTime 컬럼 값을 기준으로 오름차순 정렬해줘.”
“Driver 컬럼을 1차 기준으로 오름차순 정렬하고, 같은 드라이버 안에서는 LapTime을 내림차순으로 2차 정렬해줘.”
“1차 기준”, “2차 정렬”, “오름차순·내림차순”이라는 표현만 정확히 쓰면 AI는 by 옵션과 ascending 리스트를 조합해서 코드를 만들어준다.
4단계 — 요약, 분석 가능한 구조로 집계한다
언제 필요한가
정렬까지 끝난 데이터에서 의미 있는 패턴을 뽑아야 할 때다. 팀별 평균 랩타임, 드라이버별 최고 기록, 전체 데이터의 분포 확인. 이 단계에서 pivot_table, groupby, describe()가 등장한다.
무엇을 결정해야 하는가
4단계에서 결정할 것은 어떤 형태의 결과가 필요한가다.
그룹별 집계값만 필요하다면 groupby다. 특정 컬럼에서 동일한 값을 가진 행들을 묶고, 합계·평균·최솟값 같은 집계 함수를 적용한다. 팀별 평균 랩타임, 드라이버별 총 랩 수 같은 결과가 여기서 나온다.
행과 열이 교차하는 2차원 표 형태가 필요하다면 pivot_table이다. 엑셀 피벗 테이블과 동일한 구조다. 행에는 드라이버, 열에는 세션, 교차 지점에는 평균 랩타임 — 이런 구조가 필요할 때 쓴다. 히트맵 시각화 전처리에 pivot_table이 자주 쓰이는 이유가 바로 이 2차원 구조 때문이다.
데이터 전체의 분포와 기초 통계를 한 번에 확인하고 싶다면 describe()다. 평균, 표준편차, 최솟값, 최댓값, 사분위수까지 한 번에 출력한다. 전처리 전후 데이터 상태를 점검하는 용도로 가장 먼저 쓰는 함수다.
| 함수 | 결과 형태 | 언제 쓰는가 |
|---|---|---|
| groupby | 그룹별 1차원 집계 | 카테고리별 통계를 빠르게 뽑을 때 |
| pivot_table | 행·열 교차 2차원 표 | 히트맵 전처리, 교차 집계가 필요할 때 |
| describe() | 전체 기초통계 요약 | 데이터 분포 전체를 한 번에 확인할 때 |
AI에게 이렇게 요청할 수 있다.
“Driver 컬럼을 기준으로 그룹화해서 LapTime의 평균과 최솟값을 뽑아줘.”
“행은 Driver, 열은 Session, 교차 지점에는 LapTime 평균이 오는 피벗 테이블을 만들어줘.”
“전체 DataFrame의 기초 통계를 한 번에 확인할 수 있게 요약해줘.”
결과 형태를 머릿속에 그릴 수 있으면, 그 그림을 말로 표현하는 것만으로 AI가 코드를 완성한다.
흐름을 알면 프롬프트가 완성된다
판다스 데이터 전처리에서 기억할 것은 함수 이름이 아니라 4단계 질문이다.
지금 내 데이터가 여러 파일로 나뉘어 있는가 → 1단계, 수직으로 쌓는다. 다른 테이블의 정보를 키 기준으로 붙여야 하는가 → 2단계, 수평으로 연결한다. 특정 순서로 배열해야 하는가 → 3단계, 기준과 방향을 결정해 정렬한다. 그룹별로 집계하거나 전체 분포를 봐야 하는가 → 4단계, 결과 형태를 결정해 요약한다.
이 흐름을 따라 “지금 내가 어느 단계에 있는가”를 파악하고, 그 단계에서 “무엇을 결정해야 하는가”를 말로 표현하면 된다. 코드는 AI가 쓴다. 방향과 기준을 결정하는 것은 사람의 몫이다.
[링크 제안]
판다스 전처리를 AI에게 요청하기 전에, 판다스가 다루는 데이터 단위인 배열 구조부터 잡아두면 요청이 훨씬 정확해진다.
DataFrame 전에 판다스의 기본 단위인 Series 구조를 모르면 AI가 만들어준 코드를 읽을 수 없다.
판다스 함수의 전체 파라미터는 공식 문서에서 직접 확인할 수 있다. pandas 공식 문서