AI, 머신러닝, 딥러닝, 통계학. 요즘 이 단어들이 뒤섞여 쓰이는 걸 보면 어디서부터 이해해야 할지 막막하다. AI 역사를 흐름으로 한 번 짚고 나면 이 관계가 생각보다 선명하게 정리된다.
이 글에서는 데이터 사이언스의 전체 구조, AI 역사 연대기, 그리고 통계학과 머신러닝이 어떻게 다른지를 순서대로 다룬다. 지금 데이터 사이언스를 막 시작한 엔지니어라면 이 흐름을 먼저 잡아두는 게 이후 학습의 지도가 된다.
데이터 사이언스란 무엇인가 — AI·ML·DL·통계학의 관계
데이터 사이언스는 다양한 종류의 데이터로부터 지식과 정보를 얻기 위한 학문이다. 정의 자체는 단순하지만, 안에 무엇이 들어있는지가 중요하다.
데이터 사이언스 안에는 인공지능(AI), 머신러닝(ML), 딥러닝(DL), 그리고 통계학이 포함된다. 이들의 관계는 포함 구조로 이해하면 깔끔하다.
| 범위 | 핵심 정의 |
|---|---|
| 인공지능 (AI) | 인간의 지식습득·행동을 컴퓨터가 모방하는 개념 전체 |
| 머신러닝 (ML) | AI의 부분집합. 데이터에서 패턴을 찾아 수식으로 표현 |
| 딥러닝 (DL) | ML의 부분집합. 이미지·영상·텍스트 처리에 특화 |
| 통계학 | AI와 별도의 축. 데이터로부터 추론을 강조 |
| 데이터 사이언스 | 위 전체를 아우르는 개념 |
머신러닝은 X와 Y 데이터 사이에 숨어있는 패턴을 찾아내고, 그걸 함수식으로 표현한다. X가 주어졌을 때 Y가 무엇인지 예측하는 것이 머신러닝의 핵심이다. 딥러닝은 그 머신러닝의 소분야로, 이미지·텍스트처럼 비정형 데이터를 다루는 데 특화돼 있다. ChatGPT가 여기에 해당한다.
통계학은 AI와 다른 축에 있다. 예측보다 추론을 강조한다는 점이 결정적인 차이다. 이 구분은 뒤에서 다시 다룬다.
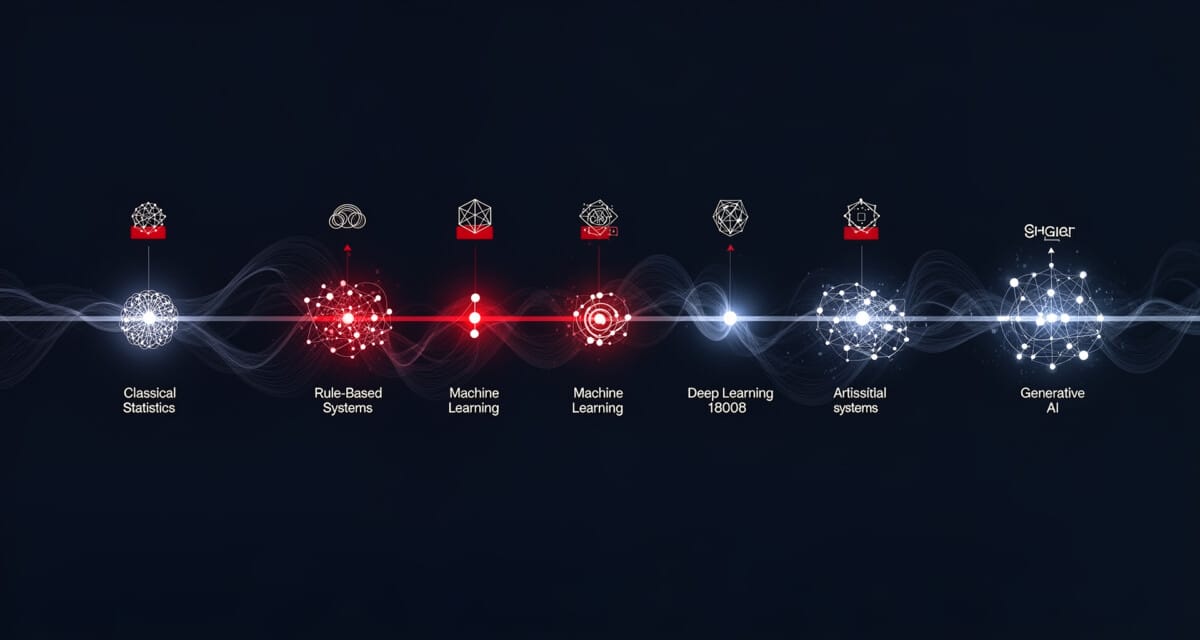
AI 역사 연대기 — 1800년대 통계학부터 ChatGPT까지
AI 역사를 시간순으로 짚어보면, 지금 우리가 쓰는 도구들이 어디서 왔는지 보인다.
1800년대 — 통계학의 시작
가설검정, 회귀분석의 뿌리가 이 시기에 놓였다. 통계학은 AI보다 훨씬 오래된 학문이다. 지금 우리가 배우는 통계 이론의 대부분은 이 시기의 유산이다.
1950년대 — 인공지능의 태동
1955년, 존 매카시가 인공지능(Artificial Intelligence)이라는 용어를 만들었다. 이 시기에 두 진영이 생겼다.
| 진영 | 창시자 | 핵심 아이디어 |
|---|---|---|
| 규칙 기반 시스템 (Rule-based) | 민스키 (MIT) | 규칙을 명시적으로 설계해 AI를 구현한다 |
| 인공신경망 (Artificial Neural Network) | 로젠블라트 (MIT) | 인간의 뉴런 구조를 수학으로 모방한다 |
같은 학교 교수였던 두 사람은 서로 다른 방향으로 인공지능을 정의했다. 그 경쟁이 수십 년간 이어졌다.
1990년대 — 머신러닝의 등장
두 진영이 통합되는 방향으로 발전하면서 머신러닝이라는 새 분야가 등장했다. 데이터에서 패턴을 학습해 예측하는 것이 핵심 목표였다. 이 시기에 규칙 기반으로 만든 소프트웨어들이 두각을 나타냈다.
- Deep Blue — 체스 세계 챔피언을 꺾은 IBM의 소프트웨어
- Watson — 미국 퀴즈 프로그램에서 인간 챔피언을 이긴 소프트웨어
2010년대 — 딥러닝과 강화학습의 부상
인공신경망 기반의 딥러닝이 대세가 됐다. 2016년 알파고가 그 상징이다. 알파고는 규칙 기반이 아닌 인공신경망으로 만들어졌다.
강화학습은 1980년대에 이미 이론이 나왔지만, 이 시기에 주목받기 시작했다. 심리학의 조건반사 원리를 수학으로 옮긴 것이다. 경험을 통해 행동을 개선하는 방식이 AI에 적용됐다.
2020년대 — AI 전성기
딥러닝과 강화학습이 결합하면서 생성형 AI의 시대가 열렸다. ChatGPT가 그 대표 사례다. AI의 개념이 태동한 건 1950년대였지만, 실제로 대중이 체감하는 건 지금 이 시점이다.
F1 팀이 레이스 전략을 설계할 때 100개의 시나리오를 분석한다고 가정하자. 1990년대였다면 엔지니어가 100개의 규칙을 직접 코딩해야 했다. 지금은 머신러닝 모델이 과거 레이스 데이터에서 패턴을 스스로 찾아낸다. AI 역사가 바로 이 차이를 만들었다.
통계학과 머신러닝은 무엇이 다른가
AI 역사를 보면 통계학과 머신러닝이 별도의 흐름으로 발전해왔다는 걸 알 수 있다. 둘의 차이는 목적에서 갈린다.
| 구분 | 통계학 | 머신러닝 |
|---|---|---|
| 핵심 목적 | 추론 — 표본으로 모집단의 특성을 유추 | 예측 — 입력 X로 출력 Y를 예측 |
| 주요 도구 | 가설검정, 회귀분석, 분산분석 | 신경망, 트리 모델, 클러스터링 |
| 데이터 유형 | 정형 데이터 중심 | 정형·비정형 모두 |
| 예측 포함? | 일부 포함 (회귀분석 등) | 핵심 기능 |
머신러닝은 “X가 주어졌을 때 Y가 무엇인가”를 맞히는 것에 집중한다. 제조 현장에서 장비 상태 데이터(X)로 불량 발생 여부(Y)를 예측하는 게 전형적인 머신러닝 활용이다.
통계학은 다르다. “지금 내가 가진 표본 데이터가 전체를 얼마나 잘 대표하는가”, “이 두 조건이 진짜로 다른가”를 따지는 게 통계학이다. 인과관계와 상관관계를 구분하는 것도 통계학적 사고에서 나온다.
통계학을 먼저 배우는 이유가 여기 있다. 머신러닝 모델이 아무리 좋아도, 그 결과를 해석하고 판단하는 기준은 통계적 추론에서 나온다.
핵심 요약
- 데이터 사이언스는 AI·ML·DL·통계학을 모두 포괄하는 개념이다
- AI 역사는 1800년대 통계학 → 1950년대 AI 태동 → 1990년대 머신러닝 → 2010년대 딥러닝 → 2020년대 생성형 AI 순으로 흘러왔다
- 통계학은 추론, 머신러닝은 예측이 핵심 목적이다
- 둘은 경쟁 관계가 아니라 서로 다른 질문에 답하는 도구다
AI 역사의 흐름을 잡았다면, 다음은 통계학이 실무에서 어떤 역할을 하는지다.
도메인 지식 없이 설명 변수를 잘못 잡으면 모델이 완벽해도 결과는 쓸모없다.
데이터 사이언스를 시작하게 된 계기가 궁금하다면 이 글도 함께 읽어두면 좋다.
AI 역사와 통계학의 학문적 배경은 Wikipedia — History of artificial intelligence에서 더 깊이 살펴볼 수 있다.